XRT manages a few well-defined kernel execution models by hiding the implementation details from the user. The user executes the kernel by OpenCL or native XRT APIs, such as clEnququeTask API or xrt::run class object, without the need of handling the control interface of the kernels explicitly inside the host code.
XRT 通过向用户隐藏实现详细信息来管理一些定义良好的内核执行模型。用户通过 OpenCL 或本机 XRT API(如 clEnququeTask API 或 xrt::run 类对象)执行内核,而无需在主机代码中显式处理内核的控制接口。
In HLS flow, depending on the pragma embedded inside the kernel code, the HLS generates RTL that resonates with XRT supported models. However, for RTL kernel, as the user has the flexibility to create kernel the way they want, it is important for RTL user to understand the XRT supported execution model and design their RTL kernel interface accordingly in order to take advantage of the automatic execution flow managed by the XRT.
在 HLS 流程中,根据内核代码中嵌入的杂注,HLS 生成与 XRT 支持的模型产生共鸣的 RTL。但是,对于 RTL 内核,由于用户可以灵活地按照他们想要的方式创建内核,因此 RTL 用户必须了解 XRT 支持的执行模型并相应地设计其 RTL 内核接口,以便利用 XRT 管理的自动执行流程。
根据这里的说明,HLS是和XRT容易结合起来使用的,HLS编译后可以生成相同功能的RTL,并且符合XRT的接口。但性能应该不及直接编写RTL。而直接编写的RTL有接入XRT的问题,需要注意XRT的接口兼容性。
At the low level, the kernels are controlled by the XRT through the control and status register that lies on the AXI4-Lite Slave interface. The XRT managed kernel’s control and status register is mapped at the address 0x0 of the AXI4-Lite Slave interface.
在底层,内核由 XRT 通过位于 AXI4-Lite 从机接口上的控制和状态寄存器进行控制。XRT 托管内核的控制和状态寄存器映射在 AXI4-Lite 从机接口的地址0x0。
The two primary supported excution models are:
- Sequential execution model
- Pipelined execution model
Sequential Execution Model
Sequential execution model is legacy (prior to 2019.1 release) default execution model supported through the HLS flow. The user can create this implemtation by specifying AP_CTRL_HS pragma at the kernel interface.
The idea of sequentially executed model is the simple one-point synchronization scheme between the host and the kernel using two signals: ap_start and ap_done. This execution mode allows the kernel only be restarted after it is completed the current execution. So when there are multiple kernel execution requests from the host, the kernel gets executed in sequential order, serving only one execution request at a time.
顺序执行模型是通过 HLS 流支持的旧版(2019.1 版本之前)默认执行模型。用户可以通过在内核接口上指定AP_CTRL_HS杂注来创建此嵌入。
顺序执行模型的思想是主机和内核之间使用两个信号的简单单点同步方案:ap_start 和 ap_done。此执行模式允许内核仅在完成当前执行后重新启动。因此,当来自主机的多个内核执行请求时,内核将按顺序执行,一次只提供一个执行请求。
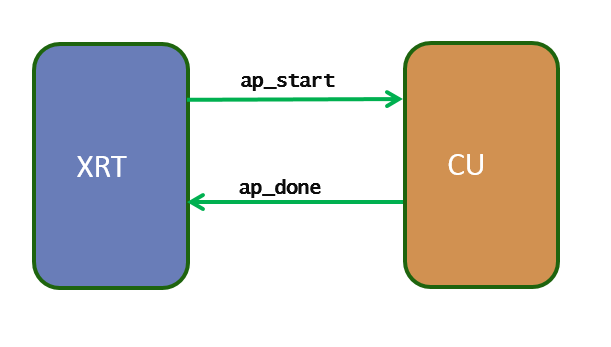
- The XRT driver writes a 1 in ap_start to start the kernel
- The XRT driver waits for ap_done to be asserted by the kernel (guaranteeing the output data is fully produced by the kernel).
- Repeat 1-2 for next kernel execution
Assume there are three concurrent kernel execution requests from the host. The kernel executions will happen sequentially as below, serving one request at a time
START1=>DONE1=>START2=>DONE2=>START3=>DONE3
Control Signal Topology
The signals ap_start and ap_done must be connected to the AXI_LITE control and status register (at the address 0x0 of the AXI4-Lite Slave interface) section to specific bits.
| Bit | Signal name | Description |
|---|---|---|
| 0 | ap_start | Asserted by the XRT when kernel can process the new data |
| 1 | ap_done | Asserted by the kernel when it is finished producing the output data |
顺序模型主要是2019.1版本之前的方式。
Pipelined Execution Model
Pipelined execution model is current default execution model supported through the HLS flow.
流水线化执模型是目前HLS的默认执行模型。
The kernel is implemented through AP_CTRL_CHAIN pragma. The kernel is implemented in such a way it can allow multiple kernel executions to get overlapped and running in a pipelined fashion. To achieve this host to kernel synchronization point is broken into two places: input synchronization (dictated by the signals ap_start and ap_ready) and output synchronization (ap_done and ap_continue). This execution mode allows the kernel to be restarted even if the kernel is working on the current (one or more) execution(s). So when there are multiple kernel execution requests from the host, the kernel gets executed in a pipelined or overlapping fashion, serving multiple execution requests at a time.
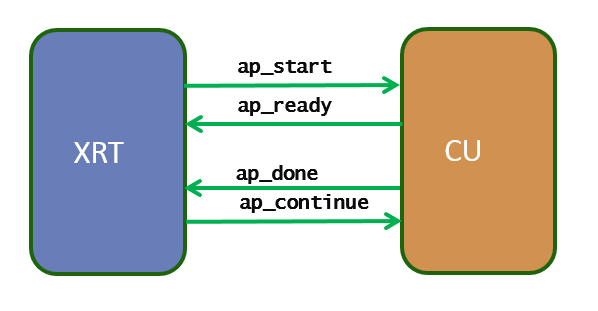
Input synchronization
- The XRT driver writes a 1 in ap_start to start the kernel
- The XRT driver waits for ap_ready to be asserted by the kernel (guaranteeing the kernel is ready to accept new data for next execution, even if it is still working on the previous execution request).
- The XRT driver writes 1 in ap_start to start the kernel operation again
Assume there are five concurrent kernel execution requests from the host and the kernel can work on three execution requests in a pipelined fashion. The kernel executions will happen sequentially as below, serving maximum three requests at a time.
START1=>START2=>START3=>DONE1=>START4=>DONE2=>START5=>DONE3=>DONE4=>DONE5
Note: As noted in the above sequence, the pipelined execution model only applicable when the kernel produces the outputs for the pending requests in-order. Kernel servicing the requests out-of-order cannot be supported by through this execution model.
注意:如上述顺序所述,流水线执行模型仅适用于内核按顺序生成挂起请求的输出。通过此执行模型不支持无序处理请求的内核。
Output synchronization
- The XRT driver waits for ap_done to be asserted by the kernel (guaranteeing the output data is fully produced by the kernel).
- The XRT driver writes a 1 in ap_continue to keep kernel running
The input and output synchronization occurs asynchronously, as a result, multiple executions are performed by the kernel in an overlapping or pipelined fashion.
Control Signal Topology
The signals ap_start, ap_ready, ap_done, ap_continue must be connected to the AXI_LITE control and status register (at the address 0x0 of the AXI4-Lite Slave interface) section to specific bits.
| Bit | Signal name | Description |
| 0 | ap_start | Asserted by the XRT when kernel can process the new data |
| 1 | ap_done | Asserted by the kernel when it is finished producing the output data |
| 3 | ap_ready | Asserted by the kernel when it is ready to accept the new data |
| 4 | ap_continue | Asserted by the XRT to allow kernel keep running |
Host Code Consideration
To execute the kernel in pipelined fashion, the host code should be able to fill the input queue with multiple execution requests well ahead to take the advantage of pipelined nature of the kernel. For example, considering OpenCL host code, it should use out-of-order command queue for multiple kernel execution requests. The host code should also use API clEnqueueMigrateMemObjects to explicitly migrate the buffer before the kernel execution.
主机代码注意事项
要以流水线方式执行内核,主机代码应该能够提前用多个执行请求填充输入队列,以利用内核的流水线特性。例如,考虑 OpenCL 主机代码,它应该对多个内核执行请求使用无序命令队列。主机代码还应使用 API clEnqueueMigrateMemObjects 在内核执行之前显式迁移缓冲区。
Note regarding the Un-managed kernels
The kernels can also be implemented without any control interfaces. As these kernels purely works on the availability of the data at its interface, they cannot be controlled (executed) from the host-code. In general these kernels are only communicating through the stream, they only work when the data is available at their input through the stream, and they stall when there is no data to process, waiting for new data to arrive through the stream to start working again.
These kernels may have scalar inputs and outputs connected through the AXI4-Lite Slave interface. The user can read/write to those kernels by native XRT APIs (xrt::ip::read_register, xrt::ip::write_register).
关于非托管内核的说明,内核也可以在没有任何控制接口的情况下实现。由于这些内核纯粹是在其接口上处理数据的可用性,因此无法从主机代码控制(执行)它们。通常,这些内核仅通过流进行通信,它们仅在通过流输入的数据可用时工作,并且在没有数据要处理时停止工作,等待新数据通过流到达以再次开始工作。
这些内核可能具有通过 AXI4-Lite 从机接口连接的标量输入和输出。用户可以通过本机XRT API读取/写入这些内核(xrt::ip::read_register,xrt::ip::write_register)。
小结
目前有两种执行模型,2019.1后默认是流水线的执行模型。执行模型就是一个和主机交互的大致流程,有控制信号,非常简单,主机可以通过寄存器获取到,应该还有中断来提醒主机。
补充
关于流水线模型的:
多个处理程序可以共同访问同一个设备上的xclbin,但是注意不要视图去加载别的xclbin,会导致其他程序返回 -EBUSY 或 -EPERM,因为把xclbin换掉了。
如果多个程序要执行同一个xclbin中的计算单元(叫kernel),先来先服务,无优先级。