在多处理器系统中,管理物理内存的模型主要有两个,UMA(Uniform Memory Access)模型的系统 和NUMA(Non-Uniform Memory Access)模型系统。它们的主要区别在于内存访问的延迟和带宽分配。
UMA模型
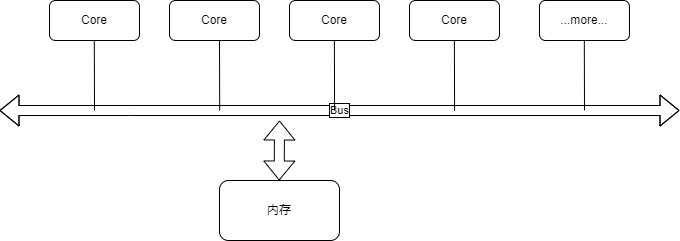
这个是早期模型了,UMA模型主要特点是各个处理器对称访问内存,所有的处理器通过共享总线互连,内存控制器也是连到总线上, 这种模型下,内存控制器是在CPU外部的。总线上的每个CPU访问内存的时间是相同的,这是一个特点。另外一个特点,同一时刻, 只有一个CPU能访问内存。这个模型下,提高性能需要不断提高CPU,总线和内存的频率。该模型,主要特点就是对称,简单,编程和 系统设计都较简单。
但是,到了后来,因为CPU性能的提升主要是靠多核并行,单核的频率已经很难有明显提升了。所以,当cpu核数量增多时, 越来越多的CPU需要竞争这个总线,性能也就出现了瓶颈。所以,后面提出了新的NUMA模型来解决这个问题。
NUMA模型
不同处理器对内存是非对称访问。该模型下,不同的CPU核心和内存器件从属于不同的Node,每个Node内有自己的内存控制器 (IMC,Integrated Memory Controller)。一般,一个CPU插槽对应一个Node。通俗说,就是系统中有多个内存控制器, 每个内存控制器会管理一部分物理内存,然后CPU的多个核会被分配使用各自的内存控制器,通常是多个核心共享一个内存控制器, 核心访问本地的内存控制器的内存,速度较快,外部的其他内存控制器当然也可以通过总线访问到,但是速度会慢些,变成了总线加 内存控制器,不过访问是没有问题的。通过多个内存控制器,把物理内存划分成了多个node,cpu核心访问自己所在(内存控制器)的node 的内存,速度较快,访问其他节点的内存,需要额外经过总线(x86上就是QPI),延迟明显更高。
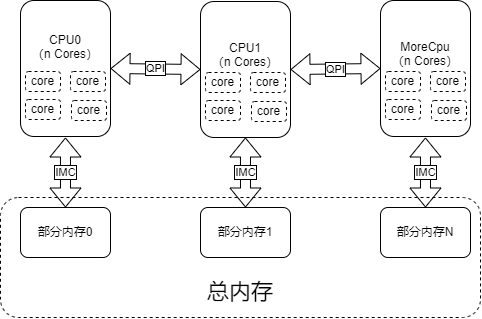
这个模型也是局部性原理的一个体现。一般一个程序使用的内存不大,仅自己所在node的内存就足够了,不需要跨node访问, 这样程序速度就可以得到提升(主要是极大减少多核心之间的内存访问的竞争)。当然,如果一个程序需要使用的内存非常大, 需要跨越node时,这个程序的运行性能就会出现明显的下降。因为访问本地的内存快,访问外部node的内存就慢。需要注意。 另外,当node数量等于1时,就等效于UMA模型。
通常,服务器系统都会使用NUMA模型,因为它CPU核心数量多,内存也大,使用NUMA可以较好的提升性能表现。 个人计算机不确定。
查看系统中NUMA node状态
可以使用numactl --hardware或lscpu命令查看系统中的numa node分配情况。
服务器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
node 0 size: 128536 MB
node 0 free: 23949 MB
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 129014 MB
node 1 free: 23557 MB
node distances:
node 0 1
0: 10 20
1: 20 10
$ lscpu
...
Model name: Intel(R) Xeon(R) Silver 4310 CPU @ 2.10GHz
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
...
个人计算机
1
2
3
4
5
6
7
8
9
10
11
12
13
14
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
node 0 size: 128597 MB
node 0 free: 61718 MB
node distances:
node 0
0: 10
$ lscpu
...
Model name: 12th Gen Intel(R) Core(TM) i7-12700K
NUMA node0 CPU(s): 0-19
...
numactl的使用
numactl除了查看系统的node信息等,还可以为一个程序的运行指定nodes和cpus。详细信息参考 man 8 numactl。
一些关键的参数:
- –membind=nodes , 仅从指定的nodes中分配内存
- –cpunodebind=nodes , 仅使用指定nods上的cpu核心来运行程序,(一个nodes上通常有多个cpu核心)
- –physcpubind=cpus ,使用指定cpu运行程序,(/proc/cpuinfo 中的 processor 域)
- –preferred=node ,优先从指定node分配内存
example:
1
2
3
4
5
6
7
8
# Run myapplic on cpus 0-4 and 8-12 of the current cpuset.
numactl --physcpubind=+0-4,8-12 myapplic arguments
# Run process on node 0 with memory allocated on node 0 and 1.
numactl --cpunodebind=0 --membind=0,1 process
# Place a tmpfs file on node 2
numactl --membind=2 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024
在一台有两个node的机器上进行测试,自测试C程序,test.c。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define ARRAY_SIZE_GB 4
#define ARRAY_SIZE_BYTES (ARRAY_SIZE_GB * 1024 * 1024 * 1024UL)
#define ELEMENT_SIZE_BYTES sizeof(uint64_t)
void initializeArray(uint64_t* array, uint64_t size) {
for (uint64_t i = 0; i < size; i++) {
array[i] = rand();
}
}
int main() {
// 分配内存
uint64_t* array = (uint64_t*)malloc(ARRAY_SIZE_BYTES);
if (array == NULL) {
printf("内存分配失败!\n");
return 1;
}
// 设置随机数种子
srand(time(NULL));
// 计时开始
clock_t start_time = clock();
// 初始化数组
initializeArray(array, ARRAY_SIZE_BYTES / ELEMENT_SIZE_BYTES);
// 计时结束
clock_t end_time = clock();
double elapsed_time = (double)(end_time - start_time) / CLOCKS_PER_SEC;
// 输出计时结果
printf("数组初始化经过clock:%ld\n",end_time - start_time);
printf("数组初始化完成!用时 %.2f 秒\n", elapsed_time);
// 释放内存
free(array);
return 0;
}
测试:
1
2
3
4
5
6
7
gcc ./test.c -O0 -o ./test
sudo numactl --membind=1 --cpunodebind=1 ./test
数组初始化经过clock:4826232
数组初始化完成!用时 4.83 秒
$ sudo numactl --membind=0 --cpunodebind=1 ./test
数组初始化经过clock:5236596
数组初始化完成!用时 5.24 秒
测试后,可以发现,使用不同node的内存的确是有一些差别的。
其他一些关于系统NUMA编程可供参考: set_mempolicy(2),mbind(2),getcpu(2),sched_setaffinity(2),cpuset(7)等
Linux Kernel 的 NUMA策略
linux内核中,有个参数和NUMA有密切关联,zone_reclaim_mode参数(/proc/sys/vm/zone_reclaim_mode), 该参数用于控制linux内核的内存回收模式。可用值包括 0,1,2,4,默认为0,关闭,1,2,4,都是不同的启用模式,可以位或。
具体解释参考 内核文档这里
- 0:禁用内存回收。内核将不会回收进程已使用的内存页(转而从其他的zone或node获取内存)。这可能会导致内存碎片的增加, 但可以减少回收内存时的延迟。在很多应用场景下可以提高效率,尤其是一些依赖内存cache比较高的程序或服务。
- 1:启用内存回收。内存回收仅发生在本地node内,回收后再获取出内存。
- 2:启用内存回收时,尝试回收低优先级进程的脏的内存cache页。被回收掉脏页内存的进程性能肯定会受影响,但是,其他node上的 程序就不会被影响了。(在回收脏页并重新分配给新进程时,该过程有明显的延迟,不如从其他node获取,所以默认就是禁用内存回收的)
- 4:启用内存回收时,启动常规的swap技术,可以以swap方式回收内存,有效限制本地node的内存分配,但应该会影响性能吧。
通常,该值保持默认关闭即可。除非是不希望内存分配跨越node,或是希望保持每个node上的程序运行情况相对独立。如果一个node上的 内存还有足够剩余,那么开启也没有问题,主要内存回收导致的性能下降基本比跨node更严重。目前主要和numa有关的问题是数据库程序。