前文介绍了内核内存管理的相关概念,伙伴系统是内存分配较底层的实现,在其基础之上,还有一些抽象的上层分配方式。
页面分配器 page allocator
Linux系统对物理内存分配的核心是伙伴系统,它就是建立在页面级之上的。 在内核中(如驱动程序),如果要分配较大的地址空间,就可以使用这一层面(页面分配器)提供的接口函数。 它提供了几个函数和宏定义函数,主要特点是只能分配 2^n(2的幂次方)个连续的物理页面。
linux对物理内存的管理,使用 node,zone,page逐级管理。page是属于zone的,不同的zone之间也有差别。 域是描述物理内存页面的。主要的zone有三个,ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM, 在32位系统和64位系统中,空间大小划分也有差别,
但不是重点。需要了解的:linux在系统初始化期间,ZONE_DMA,ZONE_NORMAL这两个域系统是会直接建立好虚拟内存 页面到物理页面的映射的。所以如果分配这两个域的页面,就不需要再建立映射了,所以像驱动程序中,申请的DMA内存, NORMAL内存,都不需要为其再进行映射。这两个区域的区别是,DMA内存的可以用于DMA传输,NORMAL内存则是通常使用。 而ZONE_HIGHMEM域,该区域里面的物理页面是没有被映射的,使用前需要建立映射。
区域和虚拟地址间映射关系参考:
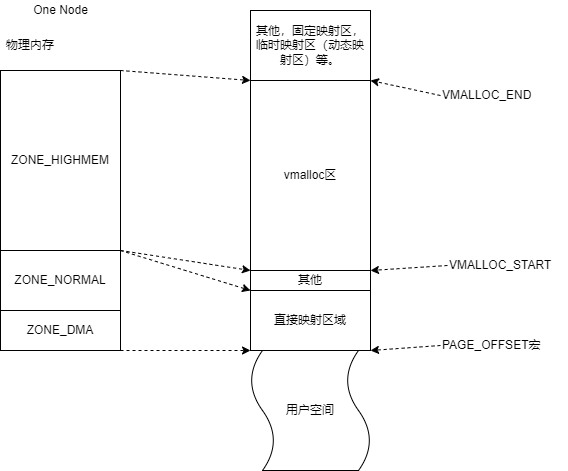
主要关注直接映射区域和vmalloc区域,区域的起始地址在内核中有宏定义决定,可能是定值,也可能是变量。其他区域在32位系统 和64位系统中,是有些差异的,虚拟地址的区域也会有些不同,不过主要是内核使用,通常与编程和用户程序没有直接关系。所以不太关注。 ZONE_HIGHMEM域中的物理内存页,更多被映射到VMALLOC区域,供程序和内存使用,也有部分被映射到其他区域,一些内核的特定用途。
页面分配API
不管是UMA还是NUMA,接口都是相同的几个。
GFP掩码
页面分配接口的一个重要参数,即GFP掩码。该掩码控制的东西较多,包括从哪个zone中分配页面,还有和内存调度等相关的控制,比较底层。 定义在头文件 /include/linux/gfp.h 或 /include/linux/gfp_types.h中。
GFP 好像是
Get Free Pages的缩写。
该掩码使用宏定义,可以分两种形式,偏底层的 __GFP_xxx和更侧重功能意义的GFP_xxx。后者是前者的一些常用的封装集成,使用后者更多。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
/**
关于宏定义的详细说明可以参考其头文件中的注释。
*/
#define GFP_ATOMIC (__GFP_HIGH|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE | \
__GFP_SKIP_KASAN_POISON | __GFP_SKIP_KASAN_UNPOISON)
#define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | \
__GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM)
#define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM)
常见使用的标记包括:
- GFP_ATOMIC : 原子分配,不会休眠,即保证进程不会被移出调度器。在非进程上下文使用,典型的就是驱动的中断处理部分,处于中断上下文,不能休眠。
- GFP_KERNEL :最常用掩码之一,可以用在进程上下文中,可能会进入睡眠状态。一般内核中非常常用,驱动的非中断处理回调函数外也都可用。
- GFP_USER :即需要给用户访问,又需要能直接被内核和硬件访问。典型的使用场景是那些需要将硬件的buff映射(map)到用户空间使用的,如显卡的显存。
- GFP_HIGHUSER : 从HIGHMEM域中分配。其他同GFP_USER。
- GFP_DMA : 限制从ZONE_DMA域中分配,可以用于DMA缓存。
API
头文件: /include/linux/gfp.h ,这里列几个
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
/* 申请部分 */
// 分配 2的order次方 个页面,返回page 结构体指针
struct page *alloc_pages(gfp_t gfp_mask, unsigned int order);
// 和上面的主要形式不同,这里返回的是page(s)的逻辑地址,即虚拟地址。另外,它会取消掉HIGHMEM的flag,即不会从HIGHMEN中获取页面
// (page * , 虚拟地址 ,物理地址之间可以转换)
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order);
/* 释放部分 */
//这里函数名里面的下划线是不对称的,需要留意一下
void __free_pages(struct page *page, unsigned int order);
void free_pages(unsigned long addr, unsigned int order);
这是两个基本的基于页面分配器的API,还有其他很多,比如这里没有涉及NUMA的node选择,其实node也是可以选择的,默认当然是本地的。 另外,如果直接申请HIGHMEM域的page,需要建立映射后才能使用。
这些基于页面分配器的API比较偏底层,一般还需要配合一些辅助的转换函数才能使用。驱动中可以使用一些上层的。
slab 分配器(slab allocator)
页面级的分配器可以方便的分配连续的物理页面,在驱动中适合分配一大块连续的物理内存空间。但很多时候,需要申请的内存很小, 如很多数据结构的申请,一般小于4KB一页大小。 此时,直接使用页面分配器就不合适,会浪费。slab分配器就是在页面级分配器的基础上,实现对更小内存的管理。
slab分配器的概念相对简单,利用页面分配器获得一些物理页面,然后在此基础上,分割出多个小内存单元,满足对小内存的需要。 不过实现很复杂,主要它考虑内存的使用速度和效率等。slab分配器有两个关键的数据结构,struct kmem_cache 和 struct slab。 具体代码不分析。
slab分配器的实现目前有三种实现算法,统称slab分配器,具体是slab,slob,slub。slab是最先实现的,能用较少的内存分配较多的单元, slob针对嵌入式环境作了优化改进,代码量小了,速度也慢了一些。slub则是减小了内存碎片,适合大型机器使用。
slab分配器在系统初始化期间会做一些初始化工作的。之后可以在系统中使用。
kmalloc
kmalloc是驱动中最常用的分配函数,它分配的空间在物理上也是连续的。该函数是建立在slab分配器之上的。
1
2
3
4
5
6
void *kmalloc(size_t size, gfp_t flags);
void kfree(void *p);
inline void *kzalloc(size_t size, gfp_t gfp)
{
return kmalloc(size, gfp | __GFP_ZERO);
}
如果slab的自己管理的内存cache不足了,它会进一步去调用alloc_pages去扩大管理的内存。如果没有内存可用,返回NULL。 gfp标记常见使用 GFP_KERNEL和 GFP_ATOMIC。
需要注意,该基于slab分配器的分配函数只能分配低端的内存(ZONE_DMA和ZONE_NORMAL域),HIGHMEM域中是不会分配的, 它在内部有相关处理。这点需要注意。
释放使用 kfree函数,该函数只能释放基于kmalloc分配的内存,这个和slab分配器的实现有关。 还有个kzalloc,可以在分配后自动初始化清零内存。
kmem_cache
slab分配器除了申请和释放小内存,还有个功能。在内核中,有些时候,需要频繁的申请和释放相同的数据结构对象。 slab分配器还有个”高速缓存“的功能。这个“高速缓存”是slab自己实现的,一种用于内核对象的缓存。 对象在slab中分配,当释放对象时,slab分配器并不会真的释放该对象占用的内存给伙伴系统,这样,下次再申请该对象 时,就可以直接获取到,不需要重新申请。此外,这部分的设计还利用了CPU的硬件高速缓存,针对特定场景可以极大提升性能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
/**
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo to identify this cache.
* @size: The size of objects to be created in this cache.
* @align: The required alignment for the objects.
* @flags: SLAB flags
* @ctor: A constructor for the objects.
*
* Cannot be called within a interrupt, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache.
*
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red` zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*
* Return: a pointer to the cache on success, NULL on failure.
*/
struct kmem_cache *kmem_cache_create(
const char *name,
unsigned int size,
unsigned int align,
slab_flags_t flags,
void (*ctor)(void *)
);
/**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache. The flags are only relevant
* if the cache has no available objects.
*
* Return: pointer to the new object or %NULL in case of error
*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);
// 释放函数,先将申请的对象释放了,最后释放cache。
void kmem_cache_free(struct kmem_cache *cachep, void *objp);
void kmem_cache_destroy(struct kmem_cache *s);
使用是先创建一个给对象申请释放用的cache,然后从该cache中申请释放对象即可。
kmem_cache_create中,name指定cache的名称,可以方便管理;size指定申请的数据结构对象大小, 是单个struct的大小,不是全部;align通常为0即可;flags标记,有一个可能会用到的, SLAB_HWCACHE_ALIGN,可以让缓存中的对象与硬件cacheline对齐,可以较好的提升性能,但会浪费内存。 ctor为对分配对象的构造函数,没有就填NULL即可。
可以通过
cat /proc/slabinfo查看相关信息,具体解释参考man 5 slabinfo
内存池 mempool
mempool(内存池)是一种用于管理和分配内存的机制。它是一种通用概念,通常是由应用程序或库实现的。不过这里特指linux内核中的内存池机制。
linux内核的内存池技术也是基于slab分配器实现的,大体思想:预先为需要的数据结构分配一定量的内存,把它们放到池中作为备用, 该数据结构在申请内存时,仍是优先从slab分配器中获取,如果分配失败,即没有公共内存了,那么此时再从之前创建的内存池中获取预先分配的内存。
内核中内存池只相当于后备缓存,它只在公共内存不足时起效,而且作用有限(和创建的大小有关,大了浪费内存,小了作用有限),有点霸占内存,但是可以从根本上保证关键应用在内存紧张时申请内存仍然能够成功。
它主要的使用场景是:如果希望关键的数据结构对象一定要分配成功,可以使用内存池,它是给紧急时备用的内存。内存池依然是优先从公共内存中申请内存的,当系统内存不足时,再从后备内存区域拿出来, 如果内存池也用完了,此时再申请,内存池会等到有可用的内存了再返回给调用者,所以说一定会分配成功,但是当内存池也用完时,它会阻塞等待一些时间,直到有可用内存再返回,所以一定会分配成功。
它和静态内存量又有些不同,因为内存池是可以动态创建删除和resize的,而静态内存定义后始终在那里,也无法改变大小,内存池像是”动态的后备内存“。
API接口和使用
头文件 : /include/linux/mempool.h
创建和销毁内存池,接口定义如下。大致用法:内存池创建时,它的后备内存的申请方式是用户指定的,是一个函数指针,由用户定义具体后备内存的申请方式,申请后给需要的数据结构对象。 申请函数指针对应代码中的alloc_fn,该函数需要能返回一个对应数据结构的对象的指针,注意是一个,mempool_create内部会调用alloc_fn函数min_nr次,这样就可以保证 有min_nr个对象的后备内存了。free_fn则是用在销毁该内存池时,释放使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
/**
* mempool_create - create a memory pool
* @min_nr: the minimum number of elements guaranteed to be
* allocated for this pool.
* @alloc_fn: user-defined element-allocation function.
* @free_fn: user-defined element-freeing function.
* @pool_data: optional private data available to the user-defined functions.
*
* this function creates and allocates a guaranteed size, preallocated
* memory pool. The pool can be used from the mempool_alloc() and mempool_free()
* functions. This function might sleep. Both the alloc_fn() and the free_fn()
* functions might sleep - as long as the mempool_alloc() function is not called
* from IRQ contexts.
*
* Return: pointer to the created memory pool object or %NULL on error.
*/
mempool_t *mempool_create(int min_nr, mempool_alloc_t *alloc_fn, mempool_free_t *free_fn, void *pool_data);
/**
* mempool_destroy - deallocate a memory pool
* @pool: pointer to the memory pool which was allocated via
* mempool_create().
*
* Free all reserved elements in @pool and @pool itself. This function
* only sleeps if the free_fn() function sleeps.
*/
void mempool_destroy(mempool_t *pool);
/* 函数指针形式 */
typedef void * (mempool_alloc_t)(gfp_t gfp_mask, void *pool_data);
typedef void (mempool_free_t)(void *element, void *pool_data);
// mempool_create中的分配后备内存 的 关键代码截取
{
...
pool->min_nr = min_nr;
pool->pool_data = pool_data;
pool->alloc = alloc_fn;
pool->free = free_fn;
...
/*
* First pre-allocate the guaranteed number of buffers.
*/
while (pool->curr_nr < pool->min_nr) {
void *element;
element = pool->alloc(gfp_mask, pool->pool_data);
add_element(pool, element);
}
}
基于内存池的内存对象的申请和释放,接口如下。mempool_alloc是申请,但它是优先从页面分配器或slab分配获取的,具体其实就是调用用户先前提供的 对象分配函数来申请,系统内存不足时,从内存池中拿取,内存池也用完了,那就会等待,直到能分配成功才返回,所以用这个函数一定会分配成功,在系统内存 不足时可能会引起等待,如果不想仔细考虑内存分配失败的情况,也可以用这个内核的内存池机制,比较方便。它以等待到有内存为止代替直接返回分配失败。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
/**
* mempool_alloc - allocate an element from a specific memory pool
* @pool: pointer to the memory pool which was allocated via
* mempool_create().
* @gfp_mask: the usual allocation bitmask.
*
* this function only sleeps if the alloc_fn() function sleeps or
* returns NULL. Note that due to preallocation, this function
* *never* fails when called from process contexts. (it might
* fail if called from an IRQ context.)
* Note: using __GFP_ZERO is not supported.
*
* Return: pointer to the allocated element or %NULL on error.
*/
void *mempool_alloc(mempool_t *pool, gfp_t gfp_mask);
/**
* mempool_free - return an element to the pool.
* @element: pool element pointer.
* @pool: pointer to the memory pool which was allocated via
* mempool_create().
*
* this function only sleeps if the free_fn() function sleeps.
*/
void mempool_free(void *element, mempool_t *pool);
// ******* mempool_alloc 函数的 关键代码 *************
{
//check ...
repeat_alloc:
//优先从公共内存获取对象内存,就是使用用户提供的通常分配函数
void *element;
element = pool->alloc(gfp_temp, pool->pool_data);
if (likely(element != NULL))
return element;
//内存池还有可用内存,就从内存池拿出对象内存
if (likely(pool->curr_nr)) {
element = remove_element(pool);
//......
return element;
}
io_schedule_timeout(5*HZ);
goto repeat_alloc;
//end here
}
高端内存使用
对于 ZONE_HIGHMEM 中的内存,需要建立映射后才能给程序使用,在系统的地址空间中,被映射到vmalloc区(VMALLOC_START和VMALLOC_END宏之间)。 内核提供了两个API方便使用:
1
2
3
void *vmalloc(unsigned long size);
void *vzalloc(unsigned long size);
void vfree(const void *addr);
vmalloc的实现主要是3点:
- 在vmalloc区分配一段连续的虚拟内存区域
- 通过页面分配器获得物理页
- 将step1中的虚拟内存区域映射到step2获得的物理页面
有一些注意点
- vmalloc申请的内存,在物理内存上不能保证是连续的,它仅是虚拟内存地址连续。如果要求DMA传输,肯定就不行。
- 由于vmalloc的实现机制,导致它的效率不如kmalloc高。
vmalloc适合数量大,但对效率要求不高,且不要求物理内存连续的场合。如内核模块加载时,内核加载模块文件,将文件读入内核内存, 就使用了vmalloc。驱动程序中建议使用kmalloc效率高,且通常不会需要太多内存。
vmalloc申请的内存,需要使用vfree释放。
IO内存映射
在内核的虚拟地址空间中,vmalloc区并不只能映射通常的DRAM内存,还可以映射IO内存。本质上都是建立虚拟内存页面和物理内存页面的映射关系。 只不过此时物理内存不是DDR,而是IO内存了。在原理上,和vmalloc基本相同,区别是vmalloc需要去通过页面分配器获得空闲的物理内存页面, 而IO内存映射不用找内存页面,而是要得到设备的IO的地址空间;其他则相同。
IO内存映射的具体实现是和CPU架构紧密相关的,不同的CPU架构上IO映射的具体实现不同,有实现为函数的,也有宏定义的,大致形式参考如下:
1
2
void __iomem *ioremap(resource_size_t offset, unsigned long size);
void iounmap(void __iomem * vaddr);
主要是两个参数,一个是物理地址,一个是映射长度,返回建立映射后的虚拟地址。使用完后记得使用iounmap来取消映射,因为映射关系是记录在内核中的。 另外,在实际使用中,有些子系统有自己的扩展版的ioremap函数,将io映射进一步封装到子系统中,如PCI总线中,有pci_iomap函数。
在完成IO映射后,可以通过虚拟地址访问IO地址空间,但内核中不建议直接这样做,因为不同平台对IO的访问可能不同(如x86中io空间独立编址, 有专门的访问IO的指令,arm则是统一编址的),内核为了兼容性,有统一的访问IO的接口,分别是按字节/半字/字访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
unsigned char ioread8 (void __iomem *vaddr);
unsigned short ioread16(void __iomem *vaddr);
unsigned int ioread32(void __iomem *vaddr);
void iowrite8 (u8 val,void __iomem *vaddr);
void iowrite16(u16 val,void __iomem *vaddr);
void iowrite32(u32 val,void __iomem *vaddr);
//一些老的接口,建议使用上面新的
unsigned char readb(void __iomem *vaddr);
unsigned short readw(void __iomem *vaddr);
unsigned int readl(void __iomem *vaddr);
void writeb(unsigned char data, void __iomem *vaddr);
void writew(unsigned short data, void __iomem *vaddr);
void writel(unsigned int data, void __iomem *vaddr);